auditissimo
KI-gestützte Interne Revision von IRBA-Ratingverfahren
Bereich
Generative KI / Audit
Partner
Hochschule Reutlingen, msg for banking ag
Stand
März 2026
Wie gut kann Generative KI die Interne Revision bei der Prüfung komplexer Ratingmodelle unterstützen? Im Forschungsprojekt auditissimo haben wir gemeinsam mit der Hochschule Reutlingen und der msg for banking ag genau dieser Frage nachgespürt — und einen modularen KI-Prototyp entwickelt, der den gesamten Prüfprozess von IRBA-Ratingsystemen Schritt für Schritt begleitet.
Hintergrund: Eine anspruchsvolle Prüfaufgabe
Kreditinstitute, die den Internal Ratings-Based Approach (IRBA) nutzen, schätzen ihre regulatorischen Kapitalparameter — Ausfallwahrscheinlichkeit (PD), Verlustquote bei Ausfall (LGD) und Forderungshöhe bei Ausfall (EAD) — auf Basis eigener statistischer Modelle. Art. 191 der Capital Requirements Regulation (CRR) verpflichtet die Interne Revision dazu, diese Ratingverfahren mindestens einmal jährlich vollständig zu prüfen.
Das klingt beherrschbar — ist es in der Praxis aber alles andere als das. Ein typischer Validierungsbericht für ein mittelgroßes Institut referenziert über vierzig regulatorische Einzelanforderungen aus CRR, EBA-Leitlinien, EBA-RTS und dem ECB Guide to Internal Models. Jede Anforderung muss mit spezifischen quantitativen Nachweisen belegt sein: Gini-Koeffizient ≥ 0,40, PSI-Schwellenwerte, Hosmer-Lemeshow-Tests, Migrationsmatrizen — die Liste ist lang. Solche Expertise ist in einem einzelnen Auditteam selten vollständig vorhanden.
Genau hier setzt auditissimo an.
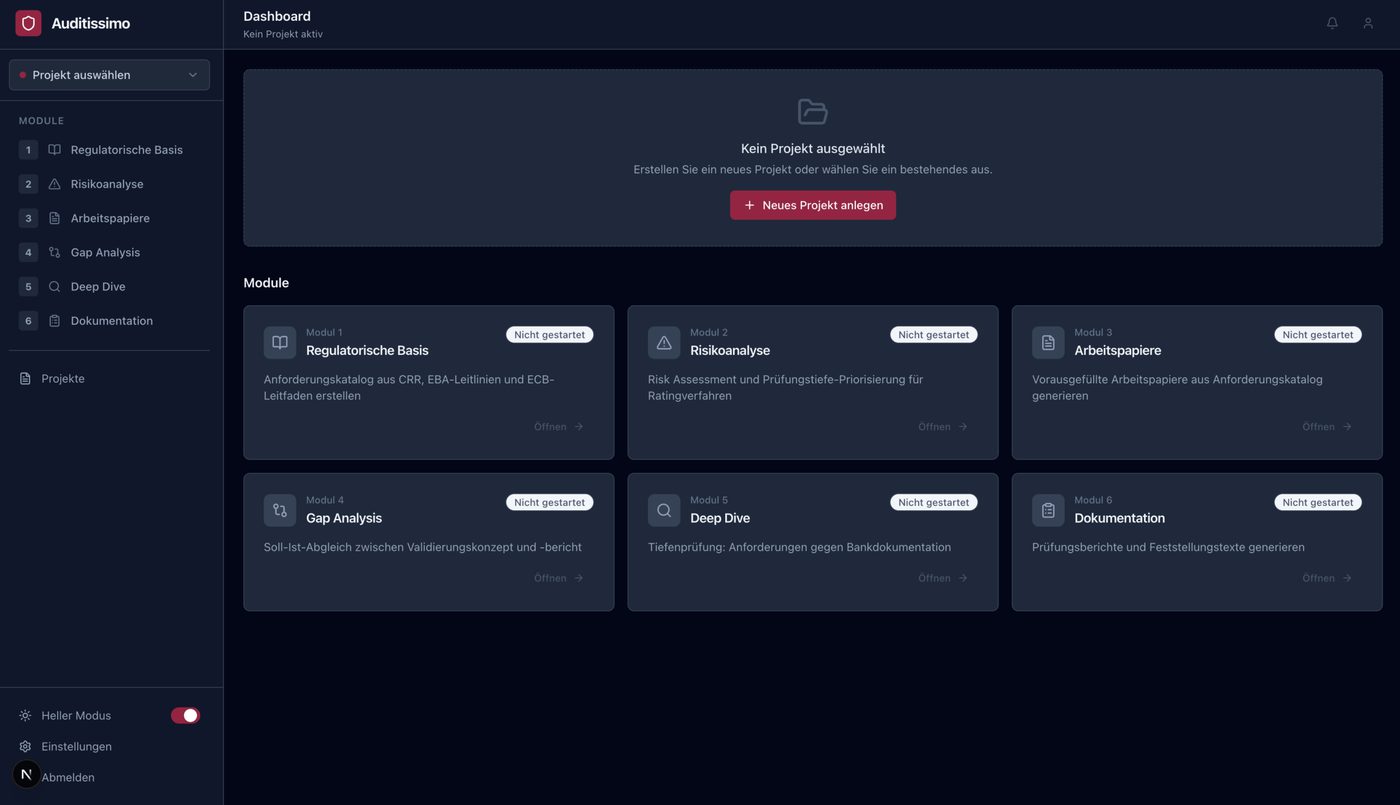
Die auditissimo-Architektur: Sechs Module, ein durchgängiger Prüfprozess
auditissimo ist kein generisches Chat-Tool. Das System bildet die tatsächliche Logik eines IRBA-Audits ab — Schritt für Schritt, Modul für Modul.
M1 — Regulatorische Basis
Eine einzige Quelle der Wahrheit
Regulatorische Anforderungen an IRBA-Modelle sind über viele Dokumente verstreut — CRR, EBA-RTS, EBA-Guidelines, ECB-Leitfäden, interne Richtlinien. Modul 1 liest alle relevanten Quelldokumente ein und zerlegt sie in atomare, testbare Einzelanforderungen. Jede Anforderung erhält eine eindeutige ID, eine Kurzbeschreibung, einen Wortlaut und die genaue regulatorische Herkunft. In der aktuellen Implementierung erzeugt das System durchschnittlich 31 Anforderungen pro regulatorischem Abschnitt — mit einer von menschlichen Prüfern bestätigten Präzision von über 90 %.
M2 — Risikobeurteilung
Nicht alle Anforderungen wiegen gleich schwer. Modul 2 bewertet jede Anforderung anhand von Modellmetadaten (Asset-Klasse, Vintage, regulatorische Vorgeschichte) und weist ihr einen Risiko-Score zu. Prüfressourcen werden so gezielt auf die kritischsten Bereiche gelenkt — ganz im Sinne des ECB-Risikobeurteilungsrahmens.
M3 — Arbeitspapier-Initialisierung
Modul 3 generiert vorausgefüllte Audit-Arbeitspapiere für jede ausgewählte Anforderung. Der administrative Aufwand für die Prüfungsvorbereitung sinkt spürbar — das Auditteam kann sich auf die inhaltliche Bewertung konzentrieren statt auf Dokumentenerstellung.
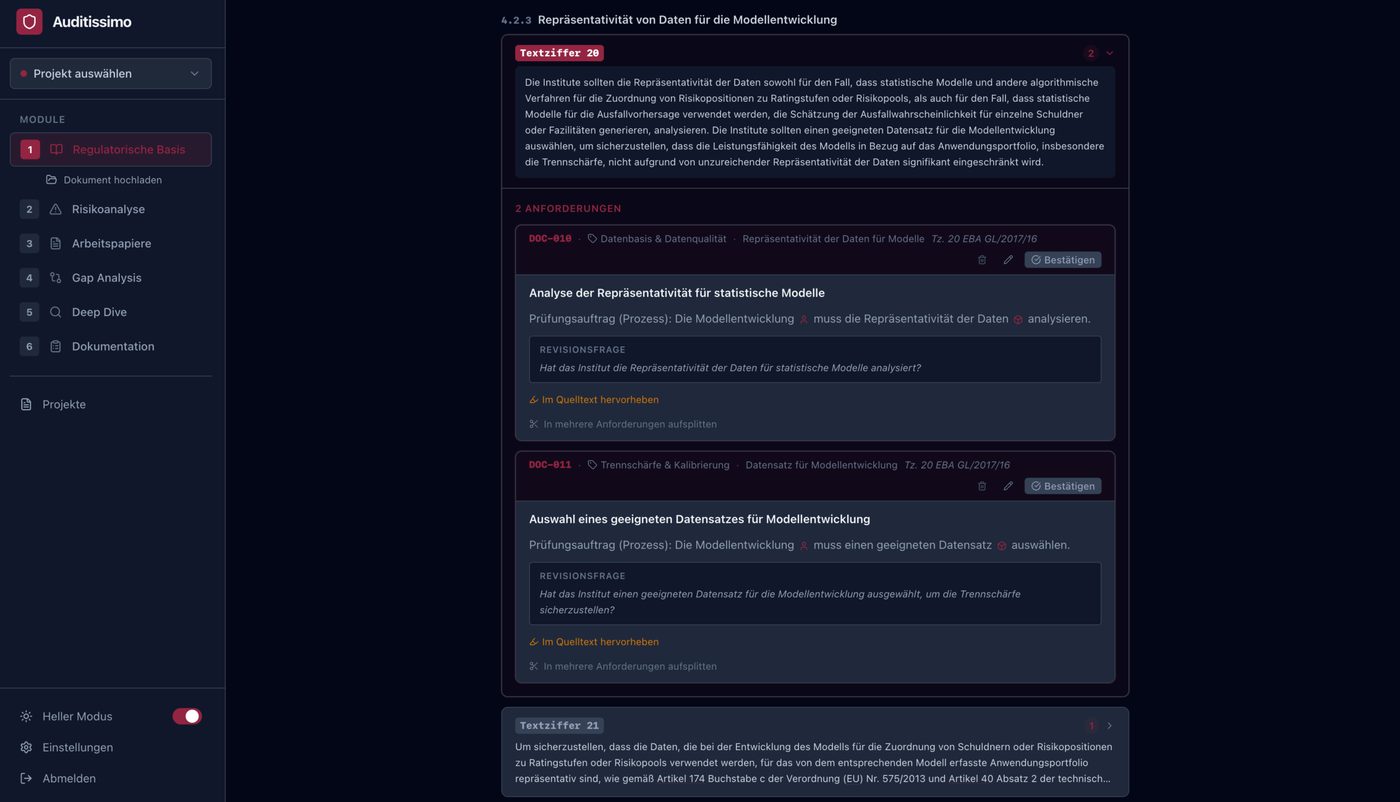
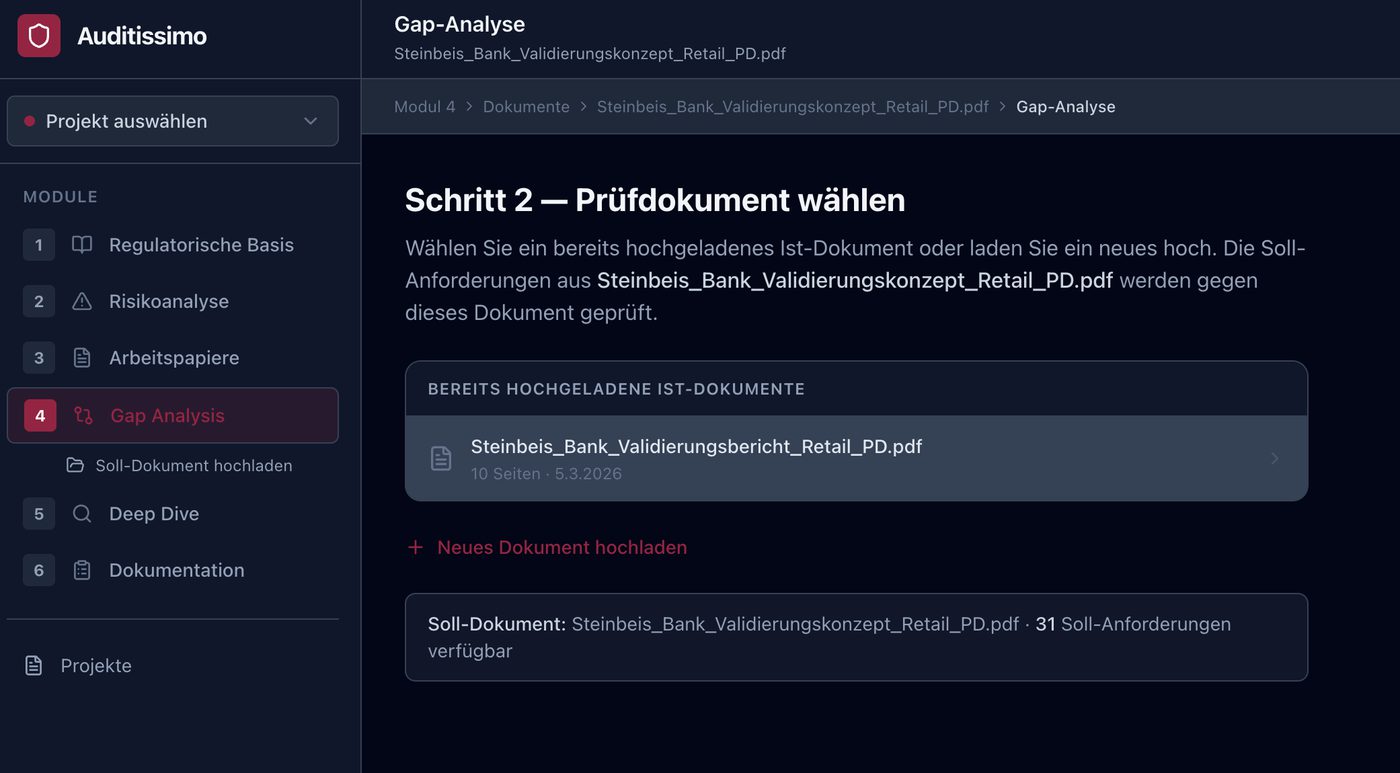
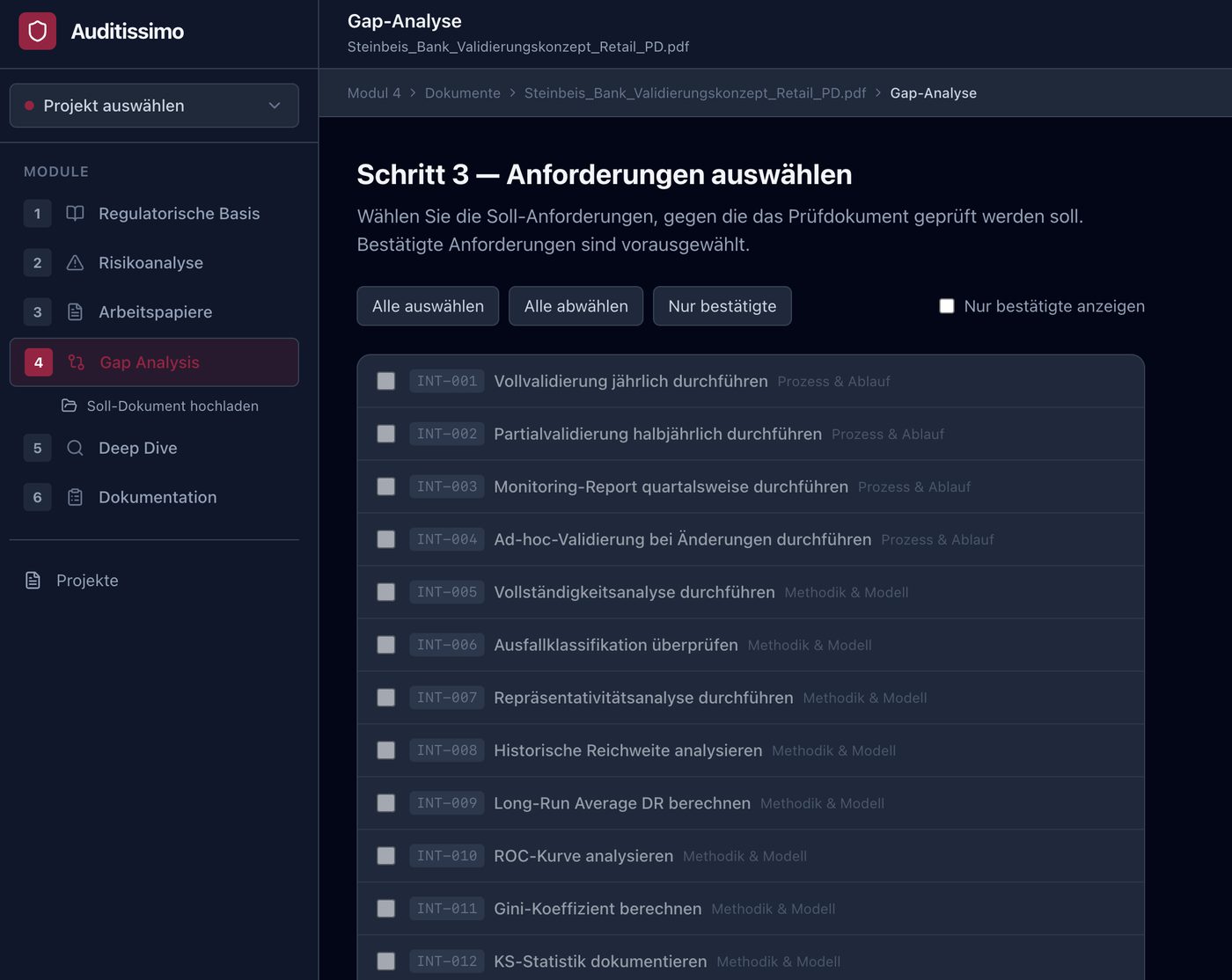
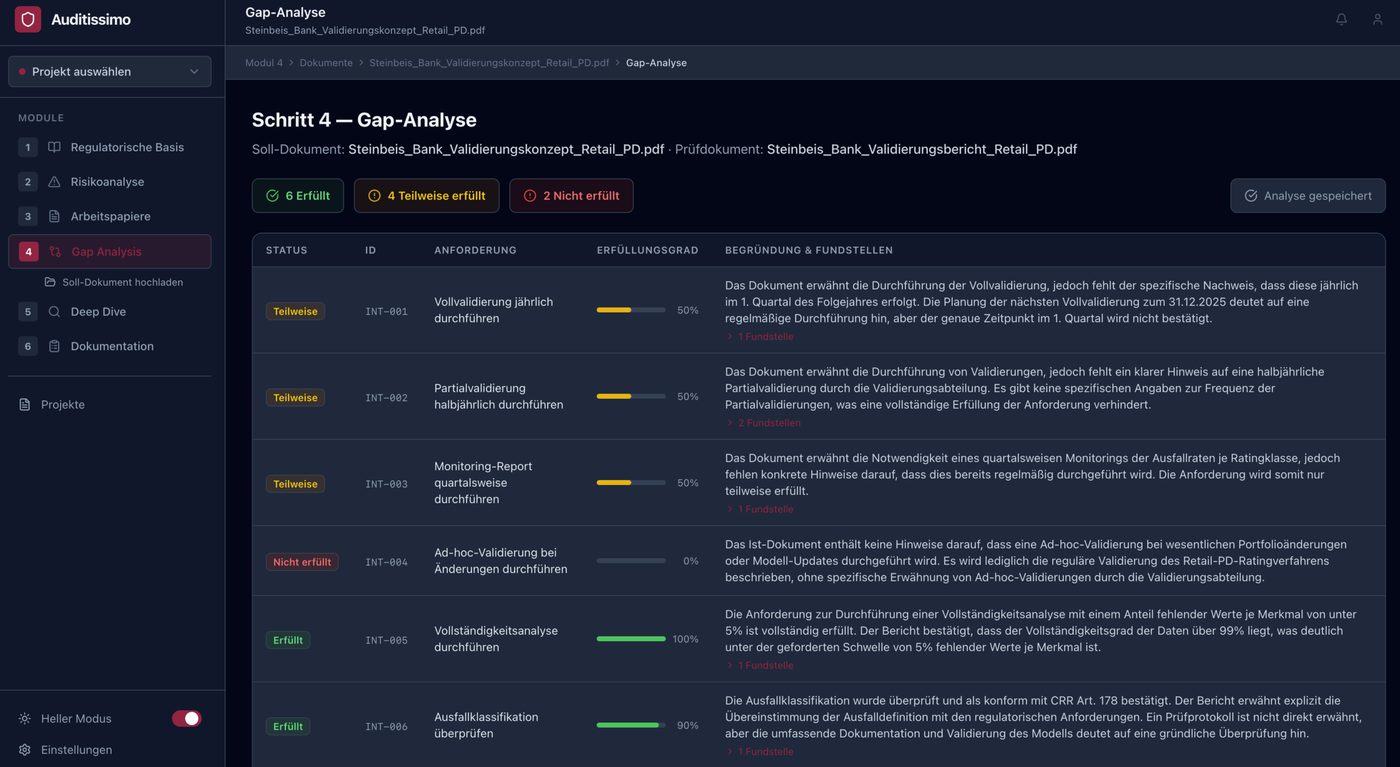
M4 — Gap-Analyse
Das Herzstück der Prüfung
Modul 4 vergleicht das Validierungskonzept (was muss geprüft werden?) mit dem Validierungsbericht (was wurde tatsächlich geprüft?). Für jede Anforderung wird ein dreistufiges Erfüllungsgrad-Urteil generiert:
- Erfüllt (80–100): Klare, vollständige Dokumentationsnachweise vorhanden
- Teilweise erfüllt (30–79): Partielle Nachweise, aber Lücken oder Unklarheiten
- Nicht erfüllt (0–29): Kein oder unzureichender Nachweis
Entscheidend: Jede KI-Bewertung ist mit Belegpassagen aus dem Prüfdokument verknüpft, sodass der Prüfer die Reasoning-Kette der KI nachvollziehen und bei Bedarf übersteuern kann. Die Temperatur der LLM-Aufrufe ist bewusst auf T = 0,1 gesetzt — Gap-Analyse ist eine Evidenz-Retrieval-Aufgabe, keine kreative Aufgabe.
M5 — Deep Dive
Anforderungen, die in M4 als „teilweise erfüllt" oder „nicht erfüllt" eingestuft wurden, werden in Modul 5 vertieft untersucht. Das Modul bohrt in spezifische Modelloutputs, Datensätze und Berechnungen — zum Beispiel: Ist der berichtete Gini-Koeffizient von 0,46 für das Retail-PD-Modell mit der im Validierungskonzept spezifizierten Methodik konsistent?
M6 — Report und Finding-Synthese
Modul 6 aggregiert die Befunde aus M4 und M5 zu strukturierten Prüfungsfeststellungen im Format des institutseigenen Audit-Managementsystems. Alle Outputs werden explizit als Erstentwurf deklariert — die abschließende Bewertung liegt immer beim verantwortlichen Prüfer.
Human-in-the-Loop: Wo KI Grenzen haben muss
auditissimo ist konsequent darauf ausgelegt, Prüferurteil zu unterstützen — nicht zu ersetzen. Wir identifizieren vier Aufgabenkategorien, bei denen menschliche Entscheidungshoheit nicht verhandelbar ist:
- H1 — Wesentlichkeitsbeurteilung: Ob eine festgestellte Lücke als Prüfungsfeststellung materiell ist, erfordert professionelles Urteilsvermögen.
- H2 — Regulatorische Interpretation: Bei mehrdeutigen Regulierungstexten kann die KI eine plausible, aber falsche Interpretation liefern. Das institutionelle Kontextwissen des Prüfers ist unverzichtbar.
- H3 — Modellmethodologische Beurteilung: Die Angemessenheit spezifischer Modellierungsentscheidungen liegt jenseits der aktuellen Fähigkeiten von General-Purpose-LLMs.
- H4 — Prüfungsurteil: Das Gesamturteil über die regulatorische Eignung des Ratingverfahrens ist eine rechtliche und professionelle Entscheidung, die beim qualifizierten Prüfer verbleibt.
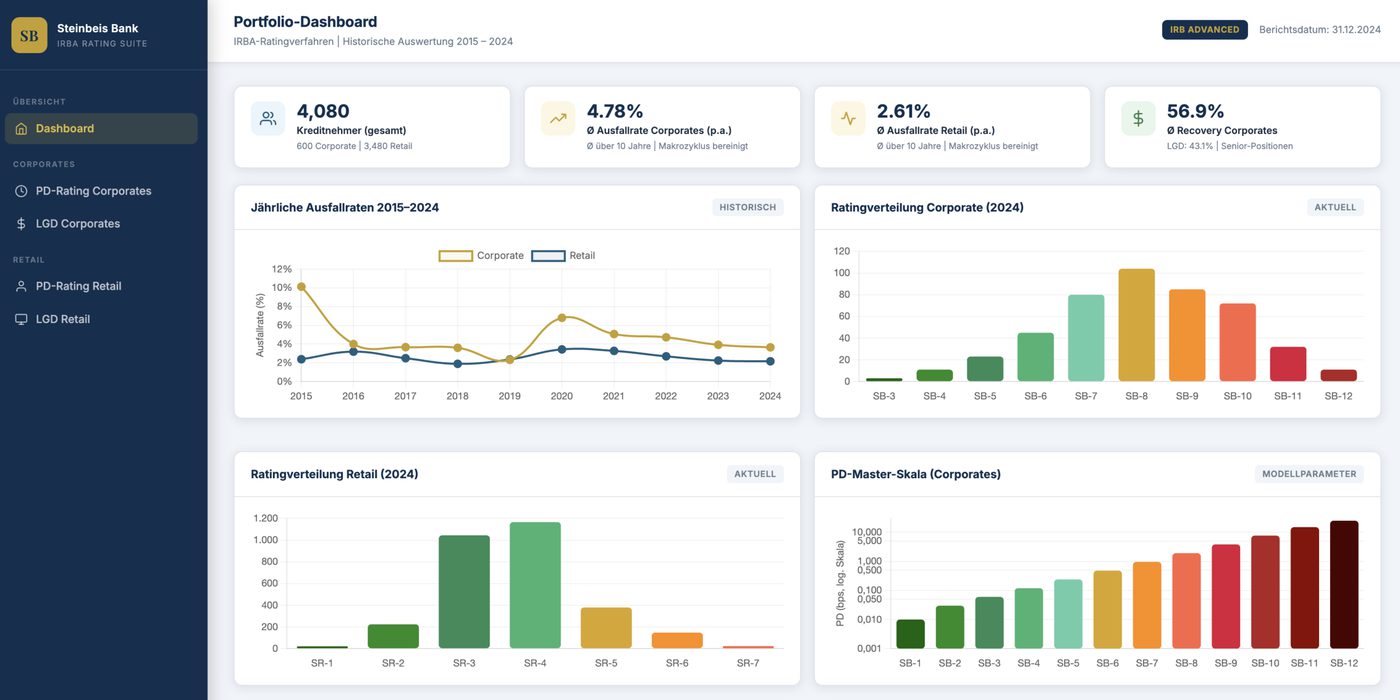
Empirische Validierung: Die Steinbeis Bank als Testumgebung
Ein zentrales methodisches Problem bei der Evaluation von GenAI-Prüfwerkzeugen: Es gibt keine öffentlich verfügbaren, annotierten Datensätze von IRBA-Compliance-Beurteilungen — solche Daten sind institutionsvertraulich. auditissimo löst dieses Problem durch eine eigens entwickelte synthetische Testumgebung: die Steinbeis Bank.
Die Steinbeis Bank ist eine vollständig parametrisierbare, synthetische Kreditinstitution mit vier produktionsnahen IRBA-Modellen (Corporate PD/LGD, Retail PD/LGD), trainiert auf 10 Jahren synthetischer Daten (2015–2024) mit realistischen makroökonomischen Zyklen.
Erste Ergebnisse: Was die KI kann — und was nicht
Im Pilotversuch wurden 24 Anforderungen aus dem Retail-PD-Validierungskontext und vier Ablationsszenarien getestet:
Das Muster ist eindeutig: Die KI erkennt vollständige Auslassungen fast fehlerfrei (F1 = 0,92). Die Leistung sinkt systematisch, je subtiler die Nicht-Compliance wird. Am schwierigsten zu erkennen sind Fälle, in denen der Bericht eine Methodik narrativ beschreibt, ohne quantitative Ergebnisse zu liefern — genau die Fälle, bei denen auch erfahrene Prüfer die meiste Aufmerksamkeit aufwenden würden.
Besonders aufschlussreich: Ein generischer Prompt erreicht nur einen F1-Score von 0,59. Durch schrittweise Verfeinerung — Rollenspezifikation als Bankprüfer, strukturiertes Ausgabe-Schema und Einbettung konkreter regulatorischer Schwellenwerte (AUC ≥ 0,70, PSI < 0,10) — steigt der Score auf 0,78. Domänenwissen muss in die Systemarchitektur eingebaut werden, nicht nur im Prompt angedeutet sein.
Was auditissimo zeigt
- Process Proximity entscheidet: Generische Dokumenten-Chat-Tools liefern für IRBA-Auditarbeit keine operationalisierbaren Ergebnisse. Die KI muss die sequenzielle Logik des Prüfprozesses selbst abbilden.
- Atomic Auditability ist Pflicht: Jede KI-Aussage muss auf eine spezifische Belegpassage rückführbar sein — für die Nachvollziehbarkeit, für den Prüfer-Override und für den regulatorischen Audit-Trail.
- Governed Human Primacy: Auditschlussfolgerungen müssen das professionelle Urteil eines qualifizierten Prüfers widerspiegeln. KI-Unterstützung ist wertvoll; KI-Substitution ist unzulässig.
Für ein mittelgroßes Institut mit zehn IRBA-Modellen bedeutet das konkret: 300 bis 400 Einzelanforderungsprüfungen pro Jahreszyklus. auditissimos Streaming-Gap-Analyse kann diese Analyse in Stunden statt Wochen abschließen — mit dem Prüfer konzentriert auf die wesentlichen Befunde statt auf mechanisches Dokumentenmatching.
Jetzt ansehen
auditissimo ist online verfügbar unter auditissimo.com. Bei Interesse an einer persönlichen Vorführung oder einem Gespräch über den Einsatz in Ihrem Haus freuen wir uns über Ihre Nachricht.
Termin vereinbarenKontakt und Live-Demo
Sie möchten auditissimo in Aktion erleben oder mehr über die Anwendungsmöglichkeiten für Ihr Haus erfahren? Sprechen Sie uns gerne an.
Prof. Dr. Dirk Schieborn
Steinbeis-Transferzentrum Data Analytics und Predictive Modelling
dirk.schieborn@steinbeis-analytics.deDas Working Paper „Generative Artificial Intelligence in Internal Audit: A Process-Integrated Framework for AI-Assisted Review of IRBA Rating Procedures under Art. 191 CRR" entstand in Zusammenarbeit von Prof. Dr. Dirk Schieborn (Hochschule Reutlingen), Prof. Dr. Volker Reichenberger (Hochschule Reutlingen) und Tim S. Körwers (msg for banking ag). Draft-Version März 2026.